Uber

Earlier in 2023 Uber announced that it was ditching its data centres and migrating completely to the cloud; a significant move for the company, which has long rolled its own infrastructure. That decision was swiftly followed by partnerships with Oracle and Google, which Uber said aimed to “diversify and decrease” supply chain risk exposure.
Now it has detailed how it migrated 4,500 stateless services to a new platform as part of its ongoing transformation that involved setting up ways to maintain and manage stateless microservices at scale. (Every week, these 4,500 stateless microservices are deployed more than 100,000 times by 4,000 engineers and many autonomous systems.)
As part of that programme, Uber has switched from its in-house development “µDeploy” platform to a new multi-cloud setup “Up”, moving “about 2,000,000 compute cores to the new platform” in 2022.
The shift has teed it up for the ongoing cloud migration with autoscaling and efficiency efforts and says the new platform means “service teams are largely distanced from the infrastructure detail of this transition.”
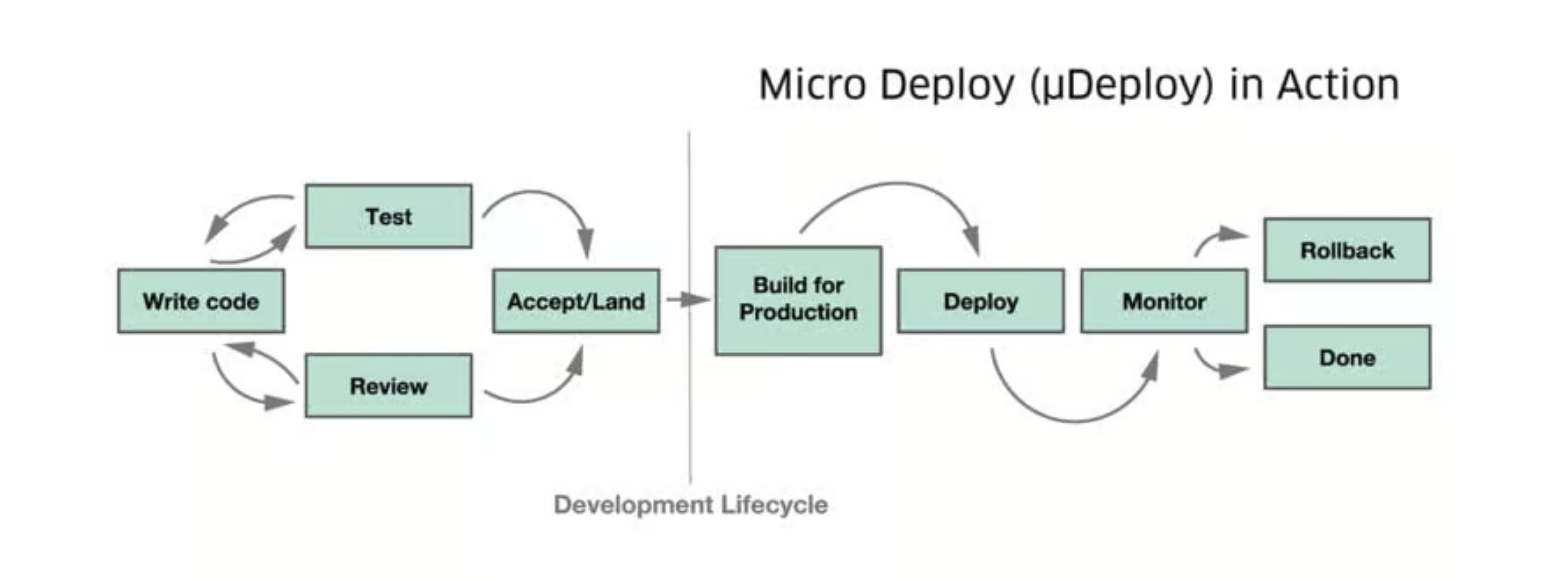
While µDeploy containerized all stateless services and abstracted away host management and placement so the infrastructure group could manage the host fleet independently of the business level microservices, service management and placement remained still highly manual, Uber explained in a Q3 blog, with engineers “still required to manage physical placement at the level of availability zones, meaning that the geographical placement of workloads was not centralized… service engineers would still have to decide not only whether to run their services in an on-prem zone, but also in which specific zone.”
See also: Uber bites the cloud bullet after "reimagining" its infrastructure: Goodbye 100k+ servers
The shift centred around a need for “engineering portability” which Uber defines as a service that can run in any zone within a region and can be moved to a new zone automatically by the infrastructure platform without any human involvement. This includes movement across public cloud providers, as well as in or out of in-prem zones.
The company has described its new platform Up as a "Multi-Cloud Multi-Tenant Federation Control Plane" – and despite offering few hard technical details about its machinery, does clarify that “the targets of the actual capacity placement and manage placement of containers on physical hosts” Kubernetes and Peloton clusters. (The latter does not refer to groups of stationary exercise bicycles, but rather, Uber’s home-brewed computer choreographer, which it has detailed here.)
Uber’s engineers note that “the effort to build the Up platform represented a substantial cultural shift when all stateless services were now being incrementally deployed using the same set of best practices and automation. Making changes to rollout policies or building out more automation for large-scale library rollouts is now possible in a centralized way, which previously required months of work.”
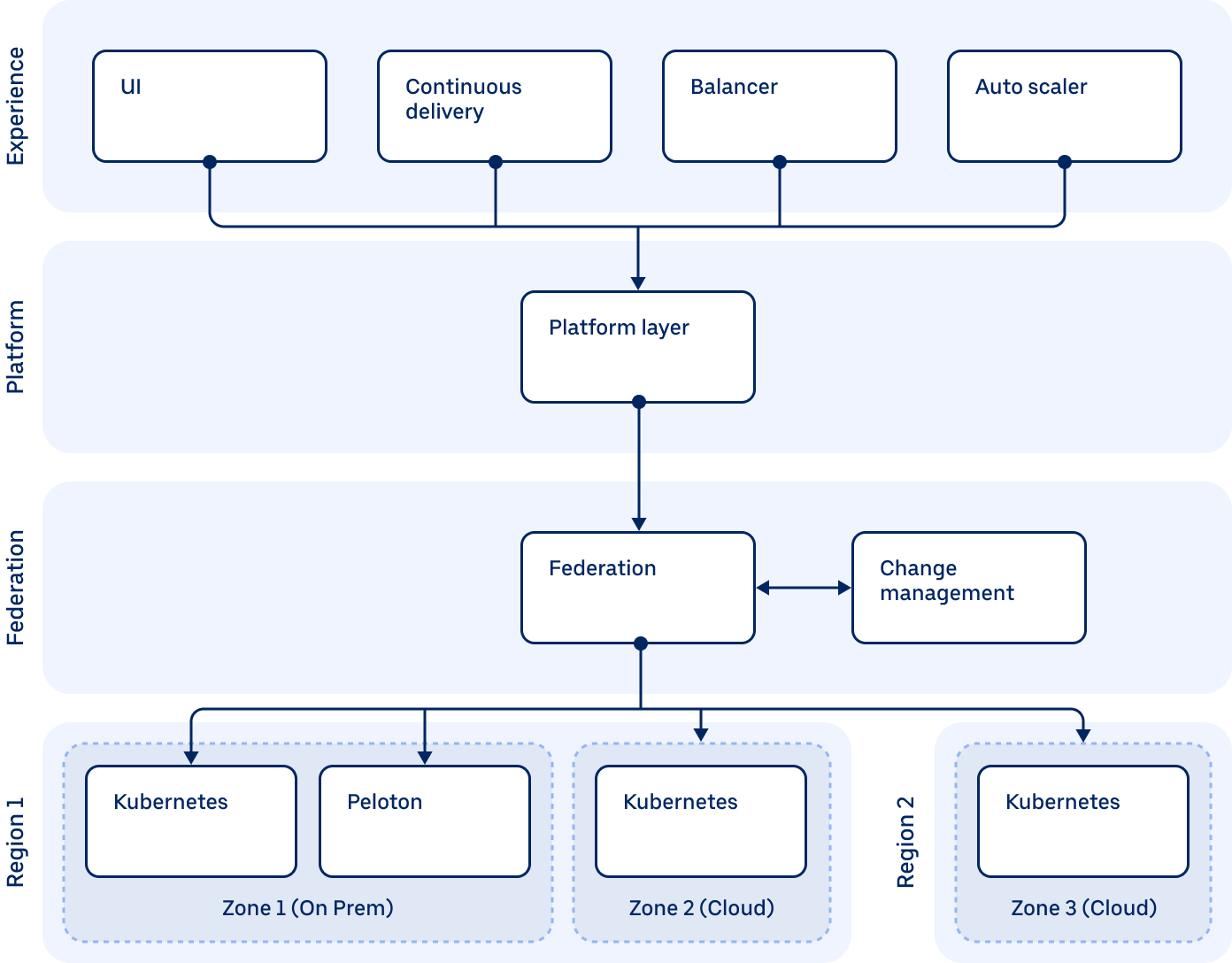
The scale of Uber’s infrastructure is not insubstantial and the company has been helpful and open about its journey, including earlier explaining how built an abstraction layer over various cloud providers’ APIs to ensure that the process for provisioning a new host is “simply a matter of calling into this abstraction layer as well as inserting a record for the host in our host catalogue” – but struggled on-premises.
See also: How Airbnb tackled its burgeoning AWS costs
As it put it in late 2022: “The story is much more complicated for our on-prem hardware. For a physical server, we first insert a record into our host catalog based on information from our physical asset tracker. Then, utilizing an in-house DHCP server that can respond to NetBoot (PXE) requests and some software to help us ensure that a host will always first attempt to boot from the network, we image the machine…” a multi-author blog noted, adding that Uber IT teams had traditionally had “wide latitude to customize the operating systems on subsets of hosts to their individual needs. This led to fragmentation, making it complex and difficult to perform fleetwide operations like OS, kernel, and security updates, porting the infrastructure to new environments, and to troubleshoot production issues.”
Its team have since pushed most workloads to containers and enforced that every host is identical at the OS layer, “containing only the essentials: a container runtime and general identity and observability services.”
To give the scale some context, for storage alone the company runs over 1,000,000 storage containers on close to 75,000 hosts with more than 2.5 million CPU cores. (Docstore, Schemaless, M3, MySQL, Cassandra, Elasticsearch, etcd, Clickhouse, and Grail are all containerised, say staff software engineers at Uber.)