meta

Meta has released a new version of its open source Llama LLM and shared details of the gigantic GPU farm used to train it.
In April 2024, Meta increased its projected annual capital expenditure by up to $10 billion and announced plans to "accelerate our infrastructure investments to support our artificial intelligence (AI) roadmap."
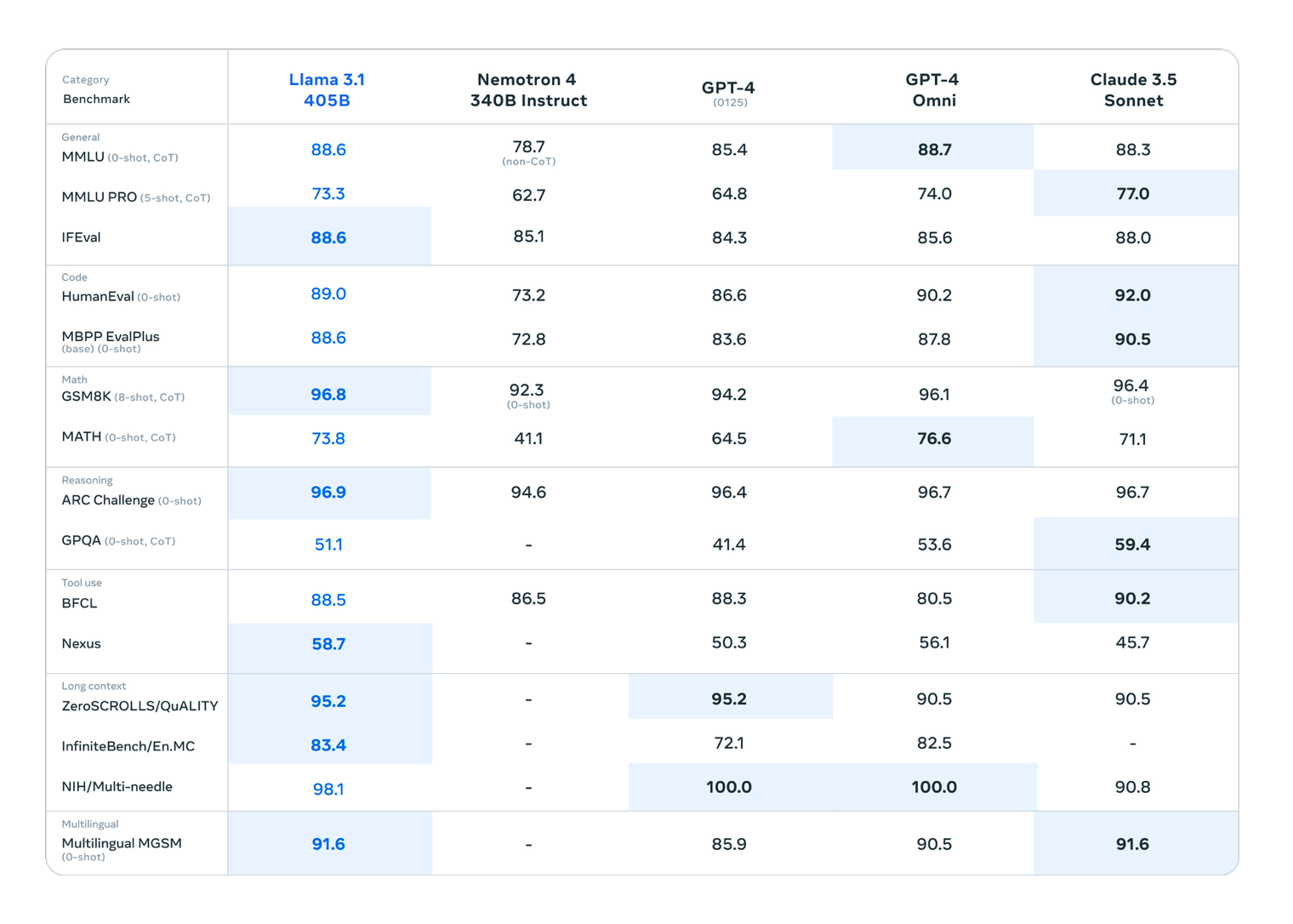
Now we can see where some of Meta's money has been going. Its new Llama 3.1 405B model was fed on a dataset with more than 15 trillion tokens using 16 thousand H100 GPUs, which makes it "the first Llama model trained at this scale."
Meta describes its latest LLM as "the first frontier-level open source AI model." It is designed to compete with the performance of closed-source LLMs like OpenAI's GPT-4 - although it hasn't matched them quite yet.
Its power was tested in 150 benchmark datasets and "extensive" human evaluations that compare the LLM against competing models.
"Our experimental evaluation suggests that our flagship model is competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet," Meta wrote. "Additionally, our smaller models are competitive with closed and open models that have a similar number of parameters.
Mark Zuckerberg took the release of his new Llama as an opportunity to pledge his commitment to the open source cause, describing the new LLM as "an inflection point in the industry" which will encourage more developers to start opening up and leaving closed models behind.
He hopes Llama will live at the centre of a thriving ecosystem which is already "primed and ready to go" with more than 25 partners.
Amazon, Databricks, and NVIDIA have launched full suites of services which enable developers to carry out fine-tuning of their models. Groq has also built "low-latency, low-cost inference serving" for all the new models, which will be available on all major clouds including AWS, Azure, Google, Oracle, and more.
"As the community grows and more companies develop new services, we can collectively make Llama the industry standard and bring the benefits of AI to everyone," Zuck wrote.
I made the closed-source vs. open-weight models figure for this moment. pic.twitter.com/Zkc6m0anNg
— Maxime Labonne @ ICML (@maximelabonne) July 24, 2024
Whilst discussing his company's committment to open source, Zuckerberg also took the opportunity to take a swipe at one of his rivals. "One of my formative experiences has been building our services constrained by what Apple will let us build on their platforms," he wrote.
"Between the way they tax developers, the arbitrary rules they apply, and all the product innovations they block from shipping, it’s clear that Meta and many other companies would be freed up to build much better services for people if we could build the best versions of our products and competitors were not able to constrain what we could build. On a philosophical level, this is a major reason why I believe so strongly in building open ecosystems in AI and AR/VR for the next generation of computing."
Meta says its latest LLM can carry out a range of tasks, including Retrieval-Augmented Generation (RAG), and is designed to "empower developers with the tools to create their own custom agents and new types of agentic behaviors."
"For the average developer, using a model at the scale of the 405B is challenging," Meta wrote. "While it’s an incredibly powerful model, we recognize that it requires significant compute resources and expertise to work with."
It added: "This is where the Llama ecosystem can help. On day one, developers can take advantage of all the advanced capabilities of the 405B model and start building immediately. Developers can also explore advanced workflows like easy-to-use synthetic data generation, follow turnkey directions for model distillation, and enable seamless RAG."
Anton McGonnell, Head of Software Products at SambaNova Systems, described the latest Llama as an "open-source behemoth matching the prowess of proprietary models".
He told The Stack: “For developers focused on building specialized AI models, the perennial challenge has been sourcing high-quality training data. Smaller expert models trained on between one and 10 billion parameters often leverage distillation techniques, utilizing outputs from larger models to enhance their training datasets. However, the use of such data from closed-source giants like OpenAI comes with tight restrictions, limiting commercial applications."
McGonnell said the latest Llama "offers a new foundation for developers to create rich, unrestricted datasets" and added: "This means developers can freely use distilled outputs from Llama 3 405B to train niche models, dramatically accelerating innovation and deployment cycles in specialized fields. Expect a surge in the development of high-performance, fine-tuned models that are both robust and compliant with open-source ethics.”
Expect to see more AI from Meta, which will continue to invest heavily in this space.
In its first quarter results for 2024, Meta wrote: "We anticipate our full-year 2024 capital expenditures will be in the range of $35-40 billion, increased from our prior range of $30-37 billion as we continue to accelerate our infrastructure investments to support our artificial intelligence (AI) roadmap. While we are not providing guidance for years beyond 2024, we expect capital expenditures will continue to increase next year as we invest aggressively to support our ambitious AI research and product development efforts."
READ MORE: Microsoft unveils a large language model that excels at encoding spreadsheets